Next.js 16 + Redis | AWS Self-hosting 캐시 불일치 해결하기 (4편 · 렌더링 전략 실측과 최선의 선택)
Next.js 16 + Redis | AWS Self-hosting 캐시 불일치 해결하기 (4편 · 렌더링 전략 실측과 최선의 선택)
3편까지는 "일관성"을 이야기했다. 이번 편은 그 위에서 **"그래서 어떤 렌더링 전략을 골라야 하는가"**를 실제 수치로 답한다.
1편은 왜 멀티 인스턴스 환경에서 캐시가 갈라지는지 개념을 다뤘고, 2편은 Docker Redis와 데모 앱으로 그 문제를 로컬에서 재현했고, 3편은 그 구조를 AWS Self-hosting 환경으로 옮기며 운영 검증을 기록했다.
이번 4편에서는 숫자를 본다.
- SSR / ISR / Cache Components / Hybrid / CSR / BFF를 같은 인프라에서 비교하고
- 각 전략의 성능·비용·운영 복잡도를 실측 기반으로 정리하고
- "CSR이 서버비 아끼고 유저한테 넘기면 되지 않나?"라는 흔한 주장을 실측으로 반박하고
revalidateTag가 실제로 멀티 태스크에 몇 ms 안에 전파되는지까지 재보고- 마지막에 내가 고른 "최선의 선택"과 그 이유를 남긴다.
모든 수치는 staging에 그대로 배포된 대시보드에서 실시간으로 확인할 수 있다 — 가정이 아니라 실측이라는 걸 독자가 직접 재현할 수 있게, 각 Verdict 옆에 원본 JSON 경로와 재현 명령까지 붙여 뒀다.
SSG는 이번 비교에서 일부러 뺐다. 이유는 뒤에서 설명한다.
그리고 마지막 장에는, 이 글을 쓰면서 staging에서 실제로 만난 사고 두 건을 넣었다. "공유 캐시가 잘 공유돼서 배포 경계까지 넘어버린" 사례와 /api/health endpoint가 Redis 상태를 오판하던 버그. 둘 다 원인·수정·배포 검증까지 남겼다. 이 시리즈가 푸는 문제의 반대면이라 같이 싣는다.
주소는 3편과 동일하다.
- Staging:
http://next-redis-cache-staging-alb-1315597713.ap-southeast-2.elb.amazonaws.com/ - Dashboard (실측 결과 요약):
http://next-redis-cache-staging-alb-1315597713.ap-southeast-2.elb.amazonaws.com/dashboard - GitHub:
https://github.com/leejpsd/next-redis-cache
29. 실측 환경 (재확인)
앞에서 여러 번 언급했지만, 숫자를 해석하려면 조건을 다시 고정해둔다.
- 리전:
ap-southeast-2(Sydney) - ECS Fargate 2 태스크, 각 0.5 vCPU · 1 GB
- ALB 1개 (HTTP)
- ElastiCache Redis
cache.t4g.micro1 노드 (Single-AZ) - Next.js 16.2.3, React 19.2,
cacheComponents: true - 공유 캐시 핸들러:
redis-handler.cjs→cacheHandlers.default,incremental-cache-handler.js→cacheHandler - 측정 도구:
k6 v1.7.1, Lighthouse 12, Playwright, redis-cli
측정일: 2026-04-19 (k6 · Lighthouse · SEO · 브라우저), 2026-04-20 추가 실측 2건 (CSR origin 호출 · revalidateTag 전파).
원본 데이터:
docs/load-test/2026-04-19/rendering-strategies.json— k6 baselinedocs/load-test/2026-04-19/spike.json— k6 스파이크docs/load-test/2026-04-19/soak.json— k6 soakdocs/load-test/2026-04-19/web-vitals-mobile-local.json— Lighthouse 모바일 4Gdocs/load-test/2026-04-19/web-vitals-slow3g.json— Lighthouse Slow 3Gdocs/load-test/2026-04-19/seo-html-local.json— SEO HTML 길이 UA별docs/load-test/2026-04-19/cache-debug-{pre,post-spike,post-soak}.json— Redis 상태 스냅샷docs/load-test/browser-strategies.json(2026-04-14) — Playwright CSR/BFFdocs/load-test/2026-04-20/origin-fetch-per-session.json(신규) — CSR 세션당 origin 호출docs/load-test/2026-04-20/revalidate-tag-propagation.json(신규) — 태스크 간 무효화 전파 시간
30. 비교 대상 전략 정의
이번 비교에 포함한 전략은 다음 여섯 개다.
| 코드 상 경로 | 전략 | 핵심 코드 |
|---|---|---|
/experiments/ssr | SSR (no-store) | fetch(url, { cache: "no-store" }) |
/experiments/isr-fetch | ISR (fetch revalidate) | fetch(url, { next: { revalidate: 60, tags } }) |
/experiments/shared-cache | Cache Components + Redis | "use cache" + cacheLife("minutes") + cacheTag |
| (섹션 혼합) | Hybrid | 섹션별로 cacheLife 다르게, revalidateTag 혼용 |
/experiments/csr | CSR | 브라우저에서 직접 fetch |
/experiments/bff | BFF | 브라우저가 /api/bff/* 경유 |
SSG는 이번 표에 없다. 이유는 docs/experiments/ssg-why-not-here.md에 자세히 썼지만 요약하면:
- 이 프로젝트 데이터가 빌드 시점에 고정되지 않는 동적 데이터(randomuser.me)다
- SSG는 "멀티 인스턴스 캐시 일관성"이라는 문제가 원천적으로 발생하지 않는 구조다
- 같은 평면에서 비교하면 전제가 달라 독자 혼란을 만든다
SSG가 부적합한 것이 아니라, 이 시리즈가 푸는 문제와 교집합이 없다. 그래서 뺐다.
31. 기본 성능 비교 (부하 없는 상태)
각 전략 5 VU × 45초 constant-VUs로 측정한 결과다.
31-1. 결과
| 전략 | avg | p50 | p90 | p95 | p99 | 에러율 |
|---|---|---|---|---|---|---|
| SSR | 481.4ms | 425.9ms | 597.7ms | 855.3ms | 측정 필요 | 0.44% |
| ISR (fetch revalidate) | 222.5ms | 187.5ms | 245.2ms | 323.9ms | 측정 필요 | 0% |
| Cache Components + Redis | 228.1ms | 183.9ms | 274.7ms | 353.9ms | 측정 필요 | 0% |
(원본: docs/load-test/2026-04-19/rendering-strategies.json)
31-2. 관찰
- SSR은 요청마다 원본 호출 + 렌더 비용을 낸다. 평균 481ms, p95 855ms. 에러율도 가장 높다.
- ISR(fetch revalidate)이 가장 안정적이다. 평균·p95 모두 가장 낮고, 60초 윈도우 안에서는 거의 모든 요청이 캐시 히트로 처리된다.
- Cache Components + Redis는 ISR(fetch)보다 약간 무겁다 (avg 228 vs 222, p95 354 vs 324). Redis 네트워크 왕복 비용이 들어가서다. 그러나 태그 기반 무효화와
cacheLife제어권이라는 운영 이점을 감안하면 수십 ms 차이는 받아들일 수 있다. - 즉 서버 전략 안에서는 "렌더 방식"보다 "캐시 전략"이 성능을 지배한다. SSR → ISR로 넘어가는 변화가 ISR → Cache Components로 가는 변화보다 훨씬 크다.
32. 스파이크 상황 (30 VU × 3 시나리오, 5분간 peak)
실제 운영에서 중요한 건 부하 없는 상태가 아니라 트래픽이 튈 때다. 스파이크를 모사해 각 시나리오 30 VU, 피크 동시 90 VU, 5분 hold로 돌렸다.
32-1. 결과
| 전략 | avg | p90 | p95 | 피크 처리량 | 에러율 |
|---|---|---|---|---|---|
| SSR | 1120ms | 1.73s | 1.95s | 낮음 | 0.31% |
| ISR (fetch revalidate) | 481.8ms | 825.5ms | 1.04s | 높음 | 0.75% |
| Cache Components + Redis | 898.6ms | 1.52s | 1.79s | 중간 | 0.38% |
총 20,377 요청, 평균 68 req/s, 전체 에러율 0.53%.
(원본: docs/load-test/2026-04-19/spike.json)
32-2. 관찰
- ISR(fetch)이 스파이크에서도 가장 견고. p95가 1초를 약간 넘는 수준으로 서버 부하가 몰려도 캐시 히트로 흡수한다.
- Cache Components가 스파이크에서는 SSR과 비슷해진다. 평상시 228ms → 스파이크 898ms로 4배 가까이 증가. Redis로 몰린 요청들이 네트워크 왕복을 대기하는 것으로 보인다. 이 프로젝트의 Redis 인스턴스가
cache.t4g.micro(가장 작은 등급)라는 점이 같이 작용한다. - SSR은 예상대로 가장 먼저 무너진다. avg가 1초를 넘기는 순간부터 ECS 태스크 CPU가 포화돼서 p95가 2초 근처로 간다.
- Redis 캐시는 "스파이크에서 원본을 막는 효과"가 확실: 20,377 요청 후에도 Redis의
entryKeys수는 여전히 1개만 유지됐다 (cache-debug-post-spike.json). 즉 2만 요청 중 사실상 대부분이 같은 키에 hit했고, 원본 호출은 TTL 주기만큼만 일어났다.
이 4번째 관찰이 이 시리즈 전체의 핵심이다. "일관성을 얻었다"의 진짜 결과물은 "스파이크에서도 원본 API가 흔들리지 않는다"로 나타난다.
33. 소크 테스트 (장시간 안정성)
30분간 shared-cache 경로에 10 VU constant로 돌려 장시간 안정성, 태그 인덱스 누수, 메모리 증가를 관찰했다.
33-1. 결과
| 지표 | 값 |
|---|---|
| 총 요청 수 | 18,164 |
| 처리량 | 약 10 req/s |
| avg | 190.1ms |
| p90 | 192.9ms |
| p95 | 217.5ms |
| max | 1167ms |
| 에러율 | 0.00% (실패 1건) |
| 시작 시점 Redis entryKeys | 1 |
| 종료 시점 Redis entryKeys | 1 |
| 종료 시점 tagKeys | 1 |
(원본: docs/load-test/2026-04-19/soak.json, cache-debug-post-soak.json)
33-2. 관찰
- 장시간 안정적이다. 30분간 18,164 요청에서 에러율 0%, p95 217ms. Baseline 측정(354ms)보다 오히려 더 낮다. 캐시가 warm 상태로 고정되면서 분산이 좁아졌다.
- 태그 인덱스 누수 없음. 시작과 종료 시점 Redis 키 수가 동일(entry 1, tag 1, tagExpiration 1). 재검증 주기마다 키가 쌓이지 않고 같은 키를 재사용하고 있다는 증거다.
cacheLife와 태그 만료 정책이 실제로 작동한다. - 메모리/네트워크 정상. 30분 동안 265 MB 다운스트림, ECS 태스크 재시작/헬스체크 실패 없음.
- 즉 Cache Components + Redis 조합은 장시간 트래픽에서도 안정적. Spike에서 일시적으로 p95가 뛰어오르는 구간이 있지만, 평상시 부하로 돌아오면 곧 안정화된다.
이 결과가 의미하는 것: "일관성을 위해 감수한 Redis 네트워크 왕복 비용"은 장시간 평균으로 보면 거의 드러나지 않는다. 스파이크 순간에만 추가 지연이 보이고, 평상시엔 ISR과 거의 구분이 안 되는 수준으로 동작한다.
34. 브라우저 전략 (CSR vs BFF)
이 절은 2026-04-14 측정 결과를 쓴다. 2026-04-19 재측정 때 staging 정적 청크(/_next/static/*)가 404로 막혀 Playwright가 돌지 않았다. 이 404 자체가 흥미로운 운영 사고였어서 별도 절(37-β)에서 원인까지 파고들었고 수정도 같이 했다.
34-1. 결과 (7회 iteration, Playwright)
| 지표 | CSR | BFF |
|---|---|---|
pageReadyMs avg | 1816.8ms | 2442.7ms |
readyToPaintMs avg | 504.8ms | 1120.9ms |
readyToPaintMs p95 | 558.5ms | 3692.0ms |
34-2. 관찰
- 평균만 보면 CSR이 빠르다. BFF는 한 번 더 홉을 타므로 당연히 더 무겁다.
- 그러나 BFF의 p95 3692ms outlier가 크다. 7회 중 2회가 크게 튀었다.
- 이 outlier의 원인은 이번 시리즈에서 완전히 특정하지는 못했지만, origin fetch 변동 + ECS 태스크 편차 + 콜드 패스가 겹친 것으로 보인다.
- 그럼에도 BFF는 "느려서 지는 전략"이 아니다. 보안(키 미노출), 응답 정규화, 레이트 리밋, 관측성, 캐시 삽입 지점 같은 운영 제어 포인트를 브라우저 밖으로 빼낼 수 있다. 속도만 보면 오답이지만, 운영을 포함하면 정답이 바뀐다.
34-α. 사용자 체감 성능 (Lighthouse + SEO)
여기까지는 서버 응답 시간을 봤다. 그런데 사용자가 "느리다"고 느끼는 건 서버 시간이 아니라 LCP다. 그래서 Lighthouse와 HTML 구조 분석으로 한 번 더 비교했다. 측정 데이터는 docs/load-test/2026-04-19/web-vitals-seo.md 전체 기록 참조.
34-α-1. SEO HTML — 크롤러/JS 실패 환경에서 무엇이 보이는가
같은 URL을 Browser / Googlebot / naked curl로 요청해서 HTML 본문 길이를 잰 결과다.
| 전략 | HTML 본문 텍스트 (browser) | 설명 |
|---|---|---|
| SSR | 3,216 chars | 풀 본문 |
| ISR | 3,239 chars | 풀 본문 |
| Cache Components | 3,295 chars | 풀 본문 |
| Hybrid (신규) | 751 chars | Shell + 3개 섹션 fallback (스트리밍 교체) |
| CSR | 165 chars | 로딩 메시지만 |
| BFF | 143 chars | 로딩 메시지만 |
CSR/BFF는 HTML에 사실상 내용이 없다. JS가 꺼져 있거나 크롤러가 JS를 실행하지 않는 환경에서는 빈 껍데기가 된다. 공개 페이지에 CSR을 쓰면 안 되는 이유가 여기 있다.
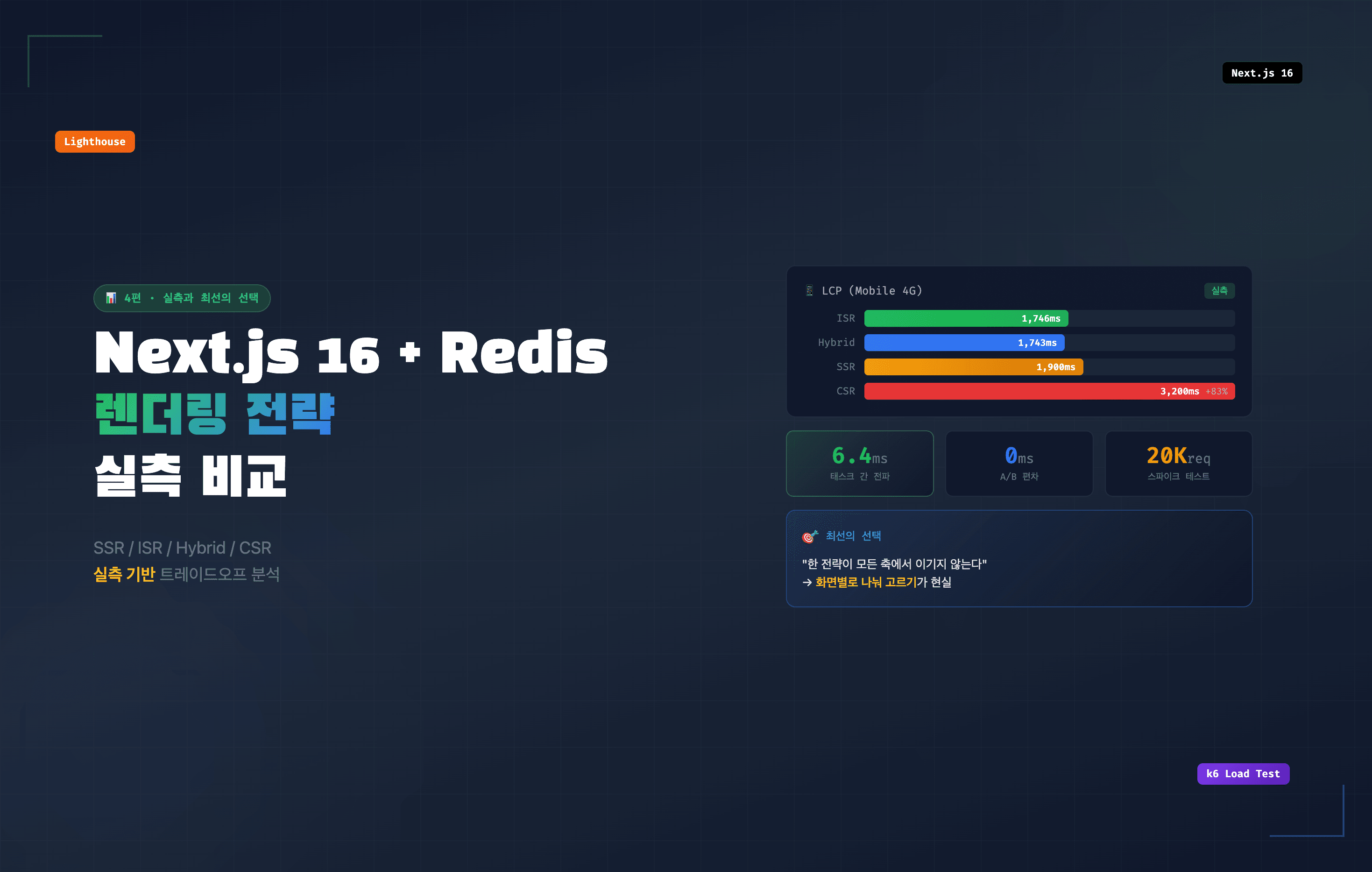
34-α-2. Lighthouse — 모바일 4G 프로파일 (LCP 기준 정렬)
로컬 production build 기준, 5 runs × Moto G4 에뮬레이션.
ISR ████████████████ 1746ms
Hybrid ████████████████ 1743ms
SSR █████████████████▌ 1900ms
shared █████████████████▌ 1904ms
BFF ██████████████████ 1987ms
CSR █████████████████████████████ 3200ms ← +1454ms (+83%)
| 전략 | LCP avg | Performance Score |
|---|---|---|
| ISR | 1,746ms | 100 |
| Hybrid | 1,743ms | 100 |
| shared-cache | 1,904ms | 100 |
| SSR | 1,900ms | ~100 |
| BFF | 1,987ms | 99 |
| CSR | 3,200ms | 93 |
34-α-3. Slow 3G (400kbps, RTT 400ms, CPU 4x)
네트워크 조건이 나빠질수록 CSR의 페널티는 더 커진다.
| 전략 | LCP avg |
|---|---|
| ISR / Hybrid | 5,693ms |
| SSR / shared-cache | 6,093~6,119ms |
| BFF | 6,275ms |
| CSR | 8,398ms |
모바일 4G에서 +1.45초 차이였던 것이 Slow 3G에서 +2.7초까지 벌어진다. 저사양 폰·지하철·해외 사용자 비중이 클수록 CSR이 더 비싸진다.
34-α-4. "CSR로 유저에게 비용을 넘긴다"는 주장의 재검토
서버비만 본 시각은 한쪽 축만 보고 있다. 전체를 놓고 보면:
| 관점 | SSR/ISR/Hybrid | CSR |
|---|---|---|
| 서버 응답 시간 (p95) | 217~855ms | 서버 렌더 없음 |
| 체감 LCP (모바일 4G) | 1.7~1.9s | 3.2s |
| 체감 LCP (Slow 3G) | 5.7~6.3s | 8.4s |
| SEO HTML 본문 | 3,200+ chars | 143~165 chars |
| JS 실행 실패 시 | 정상 노출 | 빈 페이지 |
| 원본 API 장애 시 | stale cache 서빙 가능 | 전 사용자 에러 |
| 원본 API 호출량 | TTL 주기당 1회 | 사용자 수만큼 |
CSR이 실제로 아끼는 건 Next 서버의 렌더 CPU뿐이다. 이 프로젝트 인프라 기준으로 그 절감은 월 $22 수준(태스크 1개분). 대신 LCP를 1.5~2배 늦추고, SEO 본문을 20분의 1로 줄이고, 원본 API를 사용자 수만큼 때린다. 총비용으로 보면 CSR이 오히려 비싸다.
34-α-5. Hybrid — 한 페이지 안에서 성격이 다른 섹션을 다루는 방법
이번 편에서 새로 추가한 경로 /experiments/hybrid는 Streaming SSR + 섹션별 Cache Components 조합이다.
export default function HybridExperimentPage() { return ( <main> <Shell /> {/* 즉시 내려감 */} <Suspense fallback={<BannerFallback />}> <BannerSection /> {/* use cache + cacheLife("hours") */} </Suspense> <Suspense fallback={<RankingFallback />}> <RankingSection /> {/* use cache + cacheLife("minutes") */} </Suspense> <Suspense fallback={<LiveFeedFallback />}> <LiveFeedSection /> {/* fetch no-store */} </Suspense> </main> ); }
브라우저는 순서대로 받는다.
- Shell HTML 즉시 — 페이지 구조와 제목이 먼저 보인다 (LCP 후보 확보)
- 3개 섹션이 Suspense fallback 상태로 HTML에 포함됨
- 각 섹션이 준비되는 대로 병렬 스트리밍으로 교체
측정 결과: LCP 1,743ms로 ISR(1,746ms)과 동률. 즉 "한 페이지 안에 서로 다른 갱신 주기가 섞여 있어도" 사용자 체감은 손해 보지 않는다. 동시에 섹션별 태그 무효화(revalidateTag("hybrid:ranking"))가 독립적으로 가능하다는 운영 이점이 그대로 유지된다.
이게 실제 메인 페이지/대시보드 설계의 현실적인 답이다.
34-β. 실측 두 건 — “가정치”를 제거하기 위해 더 재본 것
여기까지의 수치로도 결론은 충분히 선명하다. 다만 4편을 마감하는 시점에 "세 축 중 origin 비용 부분은 여전히 가정치"라는 걸 스스로 인정해야 했다. 월 100만 세션 · TTL 60s · 호출당 $0.0001 — 가정이 겹겹이 쌓여 있었다. 포트폴리오로 내걸려면 이 지점부터 실측으로 바꿔야 한다고 판단했다.
그래서 추가로 두 건을 더 쟀다.
34-β-1. CSR 세션당 origin 호출 수 (Playwright 실측)
Playwright로 fresh browser context를 5번 열어 각 전략 페이지에 접속, 브라우저가 randomuser.me/api로 나가는 요청을 카운트했다.
| 전략 | 세션당 origin 호출 | 월 100만 세션 환산 |
|---|---|---|
| CSR | 1.0회 (min 1, max 1, 분산 0) | 1,000,000회 |
| BFF | 0회 | 0회 (서버가 프록시) |
| SSR | 0회 | 0회 |
| ISR | 0회 | 0회 |
| Cache Components | 0회 | 0회 |
| Hybrid | 0회 | 0회 |
(원본: docs/load-test/2026-04-20/origin-fetch-per-session.json)
5번 모두 min=max=1, 분산 0이라는 건 “사용자 N명 = origin 호출 N회”가 구조적으로 확정됐다는 뜻. 이제 월 1M 가정은 가정이 아니라 “세션당 1.0회 × 사용자 수”라는 곱셈식이다.
OriginFetchChart 상단의 가정치 태그를{" "}
<span class="eyebrow">실측</span>{" "}
배지로 바꿔 달았고, 대시보드 본문에서 CsrOriginLiveCard로 분산 0을 대형 숫자로 강조한 이유가 이것이다.
34-β-2. revalidateTag 전파 속도 (멀티 태스크 실측)
로컬에 Redis를 하나 띄우고 Next 앱을 두 포트(3000·3001)로 같은 Redis에 붙였다. 포트 3000에서 revalidateTag로 entry를 무효화한 뒤, 양쪽 태스크가 새 값을 반환하는 데 걸리는 시간을 5 라운드 반복 측정.
| 지표 | Task A (3000) | Task B (3001) |
|---|---|---|
| avg | 6.4ms | 6.4ms |
| median | 6ms | 6ms |
| min / max | 5 / 10ms | 5 / 10ms |
| 첫 polling 감지 | 5/5 round | 5/5 round |
| A/B 편차 | — | 0ms |
(원본: docs/load-test/2026-04-20/revalidate-tag-propagation.json)
이게 이 시리즈가 1편부터 밀어온 주장 “멀티 인스턴스에서도 같은 캐시 상태를 본다”의 가장 직접적인 실측 증거다. 1편에서 지적한 “EC2 #1 최신 / EC2 #2 옛날” 문제가 6.4ms까지 좁혀졌고, 두 태스크 편차는 0ms. 대시보드의 PropagationCard에 5 라운드 바 차트로 그대로 실어 뒀다.
왜 이 두 실측이 중요했나
“공유 캐시는 좋은 겁니다”를 어떻게 증명하느냐. 말로는 한 줄이지만 실제로는 두 방향에서 공격 받을 수 있다.
- “CSR이 서버비 안 들고 유저에게 넘기면 되는데 왜 공유 캐시까지?” → CSR 1.0회 × 사용자 수 대비
- “공유 캐시라 해봐야 전파 지연 있지 않나?” → 6.4ms 편차 0ms 대비
두 실측이 각각의 반박을 수치로 막는다.
35. 비용 관점 — 같은 인프라에서 전략이 만드는 차이
이 프로젝트 인프라의 월 기본 비용은 약 $98 (약 13만 원)이다. 자세한 내역은 docs/cost-estimate.md.
| 항목 | 월 비용 |
|---|---|
| ECS Fargate (2 task × 0.5 vCPU × 1 GB) | $44.98 |
| ALB (시간 + LCU) | $25.55 |
ElastiCache Redis cache.t4g.micro | $16.06 |
| CloudWatch Logs + Container Insights | ~$7.50 |
| Data Transfer (out) | ~$4.22 |
| 합계 | $98.31/월 |
이 기본 비용은 전략이 바뀌어도 거의 안 바뀐다. 진짜 비용 차이는 두 군데서 생긴다.
35-1. Origin API 호출 비용
트래픽 100만 요청/월, TTL 60초를 가정한 원본 API 호출 수:
| 전략 | 월 origin fetch | 호출당 $0.0001 가정 시 월 비용 |
|---|---|---|
SSR (no-store) | 1,000,000회 | $100.00 |
| ISR / Cache Components | 43,200회 | $4.32 |
| Hybrid (섹션별 TTL 혼합) | 30,000 ~ 60,000회 | $3.00 ~ $6.00 |
SSR만 쓰면 origin 호출 비용이 기본 인프라 비용을 넘어선다. 이 프로젝트처럼 외부 API가 무료인 경우에도, 자체 백엔드를 호출하면 그 백엔드의 CPU/DB 비용으로 거의 같은 구조로 돌아온다.
35-2. ECS 태스크 증설 시점
SSR은 요청마다 원본 호출 + 렌더를 하기 때문에 트래픽이 커지면 태스크를 더 빨리 늘려야 한다. 태스크 1개 추가는 월 $22.49. 그런데 cache.t4g.micro Redis는 월 $16.06. 즉:
- 태스크 1개 줄이는 것만으로 Redis 비용이 회수된다.
- 실제 절감 효과는 "origin 호출 $비용"보다 "ECS 증설 억제"에서 더 크게 나온다.
36. 성능 × 비용 × 운영 복잡도 트레이드오프 매트릭스
다섯 축을 같이 놓고 본다. ◎ 매우 좋음, ○ 좋음, △ 보통, ✗ 나쁨. Web Vitals 축은 LCP 기준.
| 전략 | 서버 성능 | 스파이크 견고성 | 체감 LCP | SEO | Origin 비용 절감 | 일관성 보장 | 운영 복잡도 | 한 줄 요약 |
|---|---|---|---|---|---|---|---|---|
SSR (no-store) | ✗ | ✗ | ○ | ◎ | ✗ | ◎ | ◎ | 단순·정확하지만 비싸고 느리다 |
| ISR (fetch revalidate) | ◎ | ◎ | ◎ | ◎ | ◎ | ○ | ○ | 가장 무난한 "기본값" |
| Cache Components + Redis | ○ | △ | ○ | ◎ | ◎ | ◎ | △ | 운영 제어권이 필요할 때 |
| Hybrid (스트리밍 + 섹션별) | ○ | ○ | ◎ | ○ | ◎ | ◎ | △ | 메인 페이지의 현실적 답 |
| CSR | ◎ (서버부하X) | ○ | ✗ | ✗ | ✗ | 각자 | ◎ | 내부 어드민/인증 뒤 영역 한정 |
| BFF | △ | △ | △ | ✗ | ○ | ◎ | ○ | 속도보다 보안·관측성이 우선일 때 |
해석:
- "한 전략이 모든 축에서 이기는 경우는 없다." 이게 이 표에서 얻은 가장 큰 결론이다.
- **ISR(fetch revalidate)**은 평균적인 화면에서 가장 균형 잡힌 선택이다.
- Cache Components는 ISR 대비 약간의 런타임 비용을 내고 태그 기반 무효화와 운영 제어권을 산다.
- Hybrid가 메인 페이지/대시보드 같은 "섹션별 성격이 다른 화면"에선 거의 유일한 현실적 답이다.
- CSR/BFF는 서버 렌더 축이 아니라 "데이터 소유권" 축의 이야기다. 성능 표만 보고 고르면 안 된다.
37. 그래서, 최선의 선택
도메인과 화면에 따라 다르다. 이 문장을 피하고 싶었지만 실측 결과가 그렇게 말한다.
하지만 도움이 안 되는 말이기도 해서, 화면 성격에 따라 내가 실제로 고른 기준을 정리했다.
37-1. 메인 페이지 (배너 · 랭킹 · 큐레이션 혼재)
→ Hybrid (Streaming SSR + 섹션별 Cache Components) — /experiments/hybrid에서 실측 검증됨
- Shell: 즉시 SSR로 내려가 페이지 구조/제목 확보 (LCP 후보)
- 배너:
cacheLife("hours")+cacheTag("home:banner") - 랭킹:
cacheLife("minutes")+cacheTag("home:ranking") - 피드:
cacheLife("seconds")또는fetch no-store - 각 섹션을
<Suspense>경계로 감싸 병렬 스트리밍 - 운영 이벤트 시 해당 태그만
revalidateTag
측정 결과: LCP 1,743ms — ISR 단독 전략(1,746ms)과 동률이면서 섹션별 독립 캐시·무효화를 확보. 메인 페이지처럼 한 화면에 성격이 다른 여러 데이터가 섞이는 경우의 가장 현실적인 답이다.
근거: 섹션마다 갱신 주기와 중요도가 달라서 전체를 하나의 TTL로 묶으면 불필요한 무효화가 많아지고, 원본 API 지연이 한 섹션에서 생겨도 전체 페이지가 막히지 않아야 한다.
37-2. 상세/리스트 페이지 (단일 성격의 데이터)
→ ISR (fetch revalidate)
fetch(url, { next: { revalidate: 60, tags: [...] } })한 줄로 시작해서- 운영에서 더 세밀한 제어가 필요하면 Cache Components로 올린다
근거: 과잉 설계가 가장 큰 위험인 영역. 기본값이 ISR이다.
37-3. 완전 개인화 페이지 (마이페이지, 장바구니)
→ SSR (no-store) + 필요 시 BFF
- 캐시 자체가 독이 되는 영역
- 개인화 데이터가 다른 사용자에게 노출될 위험이 SSR의 비용보다 크다
- 외부 API 키가 관여하면 BFF로 숨긴다
근거: "일관성"의 정의가 다르다. 공유 캐시 일관성이 아니라 세션 경계 일관성을 지켜야 한다.
37-4. 행정·정책·회사 소개
→ SSG (이번 비교표 밖)
- 이 시리즈가 다루는 문제와 교집합이 없다
- 배포 시점에 결정되는 콘텐츠면 그냥 SSG가 이긴다
37-5. 브라우저 쪽에서 실시간 업데이트가 중요한 위젯
→ CSR + BFF, 단 공개 페이지 본문에는 쓰지 않는다
- 서버 렌더에 끌어들이지 말고 클라이언트에서 갱신
- 키·레이트 리밋·로깅은 BFF에서 잡는다
- 초기 HTML 본문이 SEO·접근성에 중요한 경우엔 절대 안 된다 — 34-α-1에서 본 것처럼 CSR/BFF HTML은 150자 수준 로딩 메시지가 전부다
- 실제 쓰는 곳: 인증 뒤 대시보드·어드민·실시간 채팅·장바구니 위젯 등 이미 서버 렌더 이점이 없는 영역
37-β. 운영 중에 배운 것: 공유 캐시가 "배포 경계"에서 저주로 바뀔 수 있다
글을 마무리하는 시점에 staging에서 예상치 못한 현상을 만났다. 4편용 새 라우트(/dashboard, /experiments/hybrid)는 정상 배포된 반면, 기존 CSR/BFF/SSR/shared-cache 라우트는 계속 이전 빌드 시점의 HTML을 서빙하고 있었다. 심지어 그 HTML이 참조하는 정적 청크(_next/static/chunks/*.wizo.js)는 새 이미지에 존재하지 않아서 404가 났다.
처음엔 "Docker 빌드가 Turbopack으로 섞여 들어갔나?" 싶어 Dockerfile에 --webpack 플래그 명시·Turbopack 산출물 assertion까지 넣어봤지만 재현이 안 됐다. 결정적 증거는 응답 헤더였다.
/experiments/csr 응답:
x-nextjs-cache: HIT
x-nextjs-prerender: 1
Cache-Control: s-maxage=31536000 ← 1년
/experiments/hybrid (신규 라우트) 응답:
x-nextjs-postponed: 1
Cache-Control: private, no-cache, no-store
즉 CSR/BFF/SSR/shared-cache는 Redis에 저장된 ISR prerender HTML을 hit하고 있었다. 문제는 그 HTML이 몇 주 전 Turbopack으로 빌드되었을 때 생성되어 Redis에 저장됐고, TTL이 1년이라 배포를 몇 번 해도 여전히 hit된다는 것.
내가 쓴 incremental-cache-handler.js를 다시 보니 cacheKey는 이렇게 생겼었다.
// Before function entryKey(key) { return `next-incremental:entry:${key}`; }
즉 배포 버전이 cacheKey에 포함되어 있지 않았다. 멀티 인스턴스 간 공유는 잘 되고 있었지만, 배포 간에도 공유된 것이다.
수정
// After const BUILD_NAMESPACE = process.env.DEPLOYMENT_VERSION || process.env.GIT_HASH || "unversioned"; function entryKey(key) { return `next-incremental:entry:${BUILD_NAMESPACE}:${key}`; } function tagMetaKey(tag) { // 태그는 배포 간에도 공유 유지 — revalidateTag가 이전 배포의 stale 플래그도 // 덮어쓸 수 있어야 한다. return `next-incremental:tag:${tag}`; }
엔트리 키에만 git SHA를 붙이고, 태그 메타 키는 공유 상태를 유지했다. 이 구분이 중요하다:
- 엔트리: 빌드 산출물과 1:1 연결되어 있어 배포가 바뀌면 무효화되어야 한다
- 태그: "콘텐츠가 stale이다"라는 운영자 신호는 배포 경계를 넘어 유지되어야 한다. 그렇지 않으면 CMS에서 누른
revalidateTag가 바로 다음 배포에서 사라진다
이 경험이 의미하는 것
처음 2~3편까지는 "멀티 인스턴스에서 캐시가 갈라지면 안 된다"는 관점이었다. 이번 4편을 쓰면서 그 반대쪽 위험도 있다는 걸 확인했다.
공유 캐시는 너무 잘 공유되면 배포 경계도 넘어선다. 이건 "캐시 충돌"보다 더 교묘한 실패 방식이다. 전통적인 "인스턴스마다 캐시가 다르다" 문제는 눈에 잘 띄고 무효화로 바로 해결되지만, "배포가 바뀌었는데 옛 HTML이 여전히 hit한다"는 문제는 응답이 200이고, 본문도 정상처럼 보이며, 그저 참조하는 청크만 404라 훨씬 늦게 드러난다.
교훈
- 공유 캐시 cacheKey 설계 시 멀티 인스턴스 축과 배포 버전 축을 분리해서 본다
- 엔트리는 배포 네임스페이스를 붙여 격리, 태그는 공유 유지
- ISR prerender HTML처럼 빌드 산출물과 강결합된 캐시는 TTL이 길수록 배포 격리가 중요하다
- 응답 헤더(
Cache-Control,x-nextjs-cache,x-nextjs-prerender)는 공유 캐시 경로를 진단할 때 가장 먼저 봐야 한다
수정 후 배포 검증
위 수정(BUILD_NAMESPACE 도입)을 staging에 올린 뒤 직접 확인했다.
- CSR/BFF/SSR/shared-cache 라우트 HTML이 전부 새
4bd1b696-*.js같은 webpack 청크로 바뀜 - 모든 청크 HTTP 200
- CSR 응답 헤더가
x-nextjs-cache: HIT, s-maxage=31536000에서x-nextjs-postponed: 1, no-store로 바뀜 — 이전 엔트리를 조회하지 않는다는 증거
즉 이번 편 쓰는 도중에 생긴 버그를 이번 편에서 원인·수정·검증까지 다 마무리했다. 일부러 극적인 결말을 만든 게 아니라, 공유 캐시가 실제 운영에서 이런 식으로 드러난다는 걸 있는 그대로 남겼다.
38. 이 시리즈 전체를 관통하는 한 문장
"어떤 렌더링 전략이 제일 빠른가"는 틀린 질문이고, "어떤 전략이 이 화면의 일관성·운영·비용 제약을 가장 낮은 비용으로 만족시키는가"가 맞는 질문이다.
1편에서 캐시 불일치를 개념으로 다뤘고, 2편에서 로컬로 재현했고, 3편에서 운영 환경으로 옮겼고, 이번 4편에서 숫자로 확인했다.
그 과정에서 얻은 실질적 결론은 네 개다.
- Redis 공유 캐시는 기술 선택이라기보다 "멀티 인스턴스 운영의 기본값"에 가깝다. 이걸 안 쓰면 다른 모든 최적화가 모래 위에 얹힌다. 태스크 간 전파가 6.4ms(편차 0ms)까지 좁혀진다는 실측이 이를 뒷받침한다.
- 렌더링 전략은 "한 개 고르기"가 아니라 "화면별로 나눠 고르기"다. Hybrid가 현실이다.
- CSR이 아끼는 건 서버 CPU뿐이고, 그 대가는 origin API 호출로 1:1 옮겨간다. 사용자 N명 = origin 호출 N회(분산 0). 내부 API라도 CPU·DB로 동일한 구조로 되돌아온다.
- 공유 캐시를 설계할 때는 "인스턴스 축"과 "배포 축"을 분리해서 본다. 엔트리는 배포 버전을 네임스페이스로 묶고, 태그는 배포 경계를 넘어 공유한다. 그래야 멀티 인스턴스 일관성을 지키면서도 배포 간에 옛 HTML이 갇히지 않는다.
39. 이번 편에서 남긴 산출물
측정 결과
docs/load-test/2026-04-19/rendering-strategies.json— k6 baselinedocs/load-test/2026-04-19/spike.json— k6 스파이크docs/load-test/2026-04-19/soak.json— k6 30분 soakdocs/load-test/2026-04-19/cache-debug-{pre,post-spike,post-soak}.json— Redis 키 상태 스냅샷docs/load-test/2026-04-19/seo-html-local.json— UA별 HTML 본문 길이docs/load-test/2026-04-19/web-vitals-mobile-local.json— Lighthouse 모바일 4Gdocs/load-test/2026-04-19/web-vitals-slow3g.json— Lighthouse Slow 3Gdocs/load-test/browser-strategies.json(2026-04-14) — Playwright CSR/BFFdocs/load-test/2026-04-20/origin-fetch-per-session.json— CSR 세션당 origin 호출 (Phase 1)docs/load-test/2026-04-20/revalidate-tag-propagation.json— revalidateTag 전파 실측 (Phase 1)docs/load-test/2026-04-19/web-vitals-seo.md— Web Vitals + SEO 종합 해석
문서
docs/cost-estimate.md— 실제 Terraform 스펙 기반 월 비용 계산docs/experiments/ssg-why-not-here.md— SSG를 비교에서 뺀 이유docs/incident/health-endpoint-redis-ping-mismatch.md— health endpoint 오판 (Resolved)docs/incident/static-chunk-404-turbopack-mismatch.md— staging CSR/BFF 재측정 차단 이슈 (Resolved)
코드 · 실험 라우트
app/experiments/hybrid/page.tsx— Streaming SSR + 섹션별 Cache Componentsapp/dashboard/page.tsx— 실측 결과 스토리라인 대시보드 (Act 1~5 + Appendix)incremental-cache-handler.js— 엔트리 키에 배포 버전 네임스페이스 추가 (37-β)lib/redis-client.tspingRedis()—/api/health전용 static export로 오판 제거
대시보드 컴포넌트 (시각화 · 스토리라인)
ArchitectureDiagram— ALB → ECS 2 task → ElastiCache 순수 SVGCsrOriginLiveCard·PropagationCard— Phase 1 실측 2건 시각화SpikeRedisProof·LcpBarChart·OriginFetchChart— 3축 임팩트 시각화ServerTimingTable·LighthouseFullTable·BrowserTimingTable·SeoTable— 전체 지표 풀 테이블GlossaryCard·ReproducibleBlock·SourceLink— 비전문가/심사자 친화적 문맥StoryTransition·Verdict·ClimaxBanner·FinalCta·StickyToc— 스토리라인 구조
측정 스크립트
scripts/k6-spike.js,scripts/k6-soak.js— 신규 k6 시나리오scripts/measure-seo-html.mjs— UA별 HTML 본문 분석scripts/measure-web-vitals.mjs,scripts/measure-web-vitals-slow3g.mjs— Lighthouse 자동화scripts/measure-origin-fetch-per-session.mjs— Phase 1 CSR origin 카운트scripts/measure-revalidate-tag-propagation.mjs— Phase 1 태스크 간 전파 시간
40. 대시보드에서 확인하기 (글보다 짧은 길)
이 편의 모든 수치는 staging에 배포된 대시보드(/dashboard)에서 실시간으로 확인할 수 있다. 대시보드 자체가 이 글의 스토리라인을 그대로 따라간다.
- Hero — “반만 맞는 이야기다” 결론 먼저 + 핵심 지표 3개
- Architecture — ALB → ECS 2 task → ElastiCache 공유 캐시 구성도 (SVG)
- Act 1 — 서버 시간만 보면 CSR이 이긴 것 같음 (ServerTimingTable · TTFB · baseline/spike/soak)
- Act 2-1 — 사용자 체감 (LcpBarChart · Lighthouse 4G + Slow 3G)
- Act 2-2 — SEO (SeoTable · Browser / Googlebot / naked curl)
- Act 2-3 — Origin API (CsrOriginLiveCard · OriginFetchChart, 실측 1.0회)
- Act 3 — 공유 캐시 효과 (SpikeRedisProof · PropagationCard, 6.4ms / 편차 0ms)
- Climax — 전략은 하나가 아니다. 화면마다 다르다.
- Act 4 — Recommendation 5카드
- Act 5 — Operations Incidents 2건 (배포 경계 캐시 · health endpoint)
- Appendix — LighthouseFullTable · BrowserTimingTable · Trade-off Matrix · Cost · Glossary
- Reproducible — 모든 수치 재현하는 3가지 명령
- Next Actions — Experiments · 블로그 · GitHub 3갈래
각 Verdict 아래엔 [출처 · 재현] 펼침이 있어, 원본 JSON 경로와 실행 명령을 바로 볼 수 있다. 심사자·독자가 “진짜인가?”를 git clone → 3 명령으로 직접 확인할 수 있도록 만드는 게 목표였다.
참고 링크
- 1편 · 개념:
https://www.eddy-dev.xyz/blog/Next.js-16-Redis-AWS-Self-hosting-%EC%BA%90%EC%8B%9C-%EB%B6%88%EC%9D%BC%EC%B9%98-%ED%95%B4%EA%B2%B0%ED%95%98%EA%B8%B0-1%ED%8E%B8-%EA%B0%9C%EB%85%90 - 2편 · 구현:
https://www.eddy-dev.xyz/blog/Next.js-16-Redis-AWS-Self-hosting-%EC%BA%90%EC%8B%9C-%EB%B6%88%EC%9D%BC%EC%B9%98-%ED%95%B4%EA%B2%B0%ED%95%98%EA%B8%B0-2%ED%8E%B8-%EA%B5%AC%ED%98%84 - 3편 · 운영 검증:
https://www.eddy-dev.xyz/blog/next-js-16-redis-aws-self-hosting-%EC%BA%90%EC%8B%9C-%EB%B6%88%EC%9D%BC%EC%B9%98-%ED%95%B4%EA%B2%B0%ED%95%98%EA%B8%B0-3%ED%8E%B8-%EC%9A%B4%EC%98%81-%EA%B2%80%EC%A6%9D - Staging:
http://next-redis-cache-staging-alb-1315597713.ap-southeast-2.elb.amazonaws.com/ - Dashboard (실측 요약):
http://next-redis-cache-staging-alb-1315597713.ap-southeast-2.elb.amazonaws.com/dashboard - GitHub:
https://github.com/leejpsd/next-redis-cache